What Do Adversarial Examples Tell Us About Prompt Injections?
It’s been more than 3 years since the concept of a prompt injection was first popularized, and in that time AI has gone from “barely coherent conversations” to “autonomous discovery of novel vulnerabilities in the Linux kernel”. But models remain highly credulous and easily misled; a recent paper was able to reliably circumvent refusals by simply appending specious reasoning traces which justify a given request. Why is prompt injection such a difficult problem to solve? The mixed results from a decade of research on adversarial examples in image classification are instructive.
An adversarial example is an input intentionally constructed to cause a failure in a machine learning system, such as an email crafted to bypass spam filters. The setting that has drawn the most attention in recent years is that of imperceptible modifications to images that cause misclassifications by neural networks.
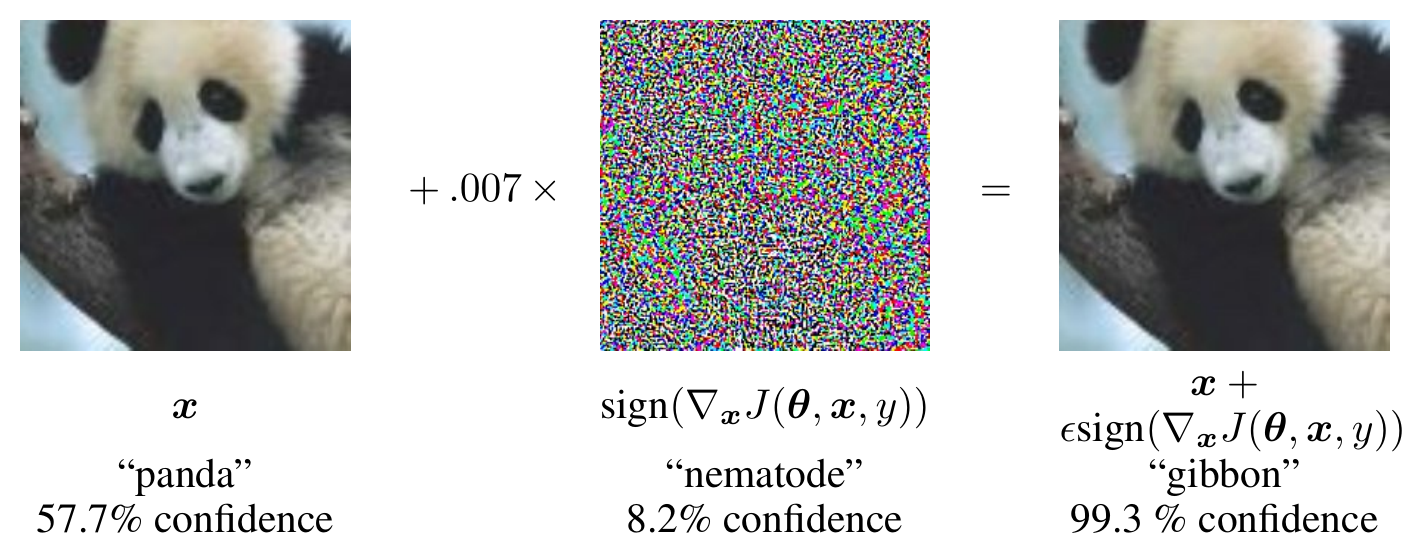
Over the years, researchers have studied different instantiations of this problem that vary in the kind of modifications the adversary is allowed to make. The most widely studied whitebox threat model assumes that:
- The adversary can make bounded perturbations to real input images
- The adversary has full knowledge of the classifier and defenses (including all weights)
- The adversary can afford to compute many (thousands) predictions and gradient steps
This threat model maps onto some low-to-moderate security threats in the real world, such as evading content filters or sabotaging self-driving cars, but much of the research in this area over the last decade has been motivated by the intellectual challenge of adversarial examples rather than real-world threats to AI systems (Gilmer et al., 2019).
There are a number of differing explanations for where adversarial examples come from. The closest-to-consensus view is that because neural network models are less constrained in their processing of information than humans, they often learn to leverage spurious statistical correlations during training (Ilyas et al., 2019, Geirhos et al., 2018). Test accuracy suffers when these correlations no longer hold, due to out-of-sample data or intentional scrambling by an adversary (Yin et al., 2019, Geirhos et al., 2020).
The early days of research on adversarial examples were marked by a flurry of clever ideas each claiming large improvements in robustness. Researchers often declared victory prematurely after evaluating against a handful of basic attacks that were not tailored to proposed defenses. For instance, injecting random noise during inference or introducing non-differentiable operations made direct gradient computation impossible, but could also be easily addressed by approximating the gradient. Many successful careers were built on swatting down spurious claims and establishing careful evaluation protocols (Carlini et al., 2019, Croce and Hein, 2020) that paved the way for standardized benchmarks like RobustBench.
The RobustBench leaderboard is the canonical record book for tracking the performance of image classifiers against a standardized battery of whitebox attacks. Technically, the reported numbers are merely upper bounds on model performance as it is possible that more effective attacks are discovered in the future, but the constraint of making small perturbations to existing images is lim iting, and there have been years of intensive research into new attack methods. Currently, the best CIFAR-10 classifier stands at 93.7% “clean accuracy” on the original test set, and drops to 73.7% “robust accuracy” when evaluated on the adversarially perturbed test set.
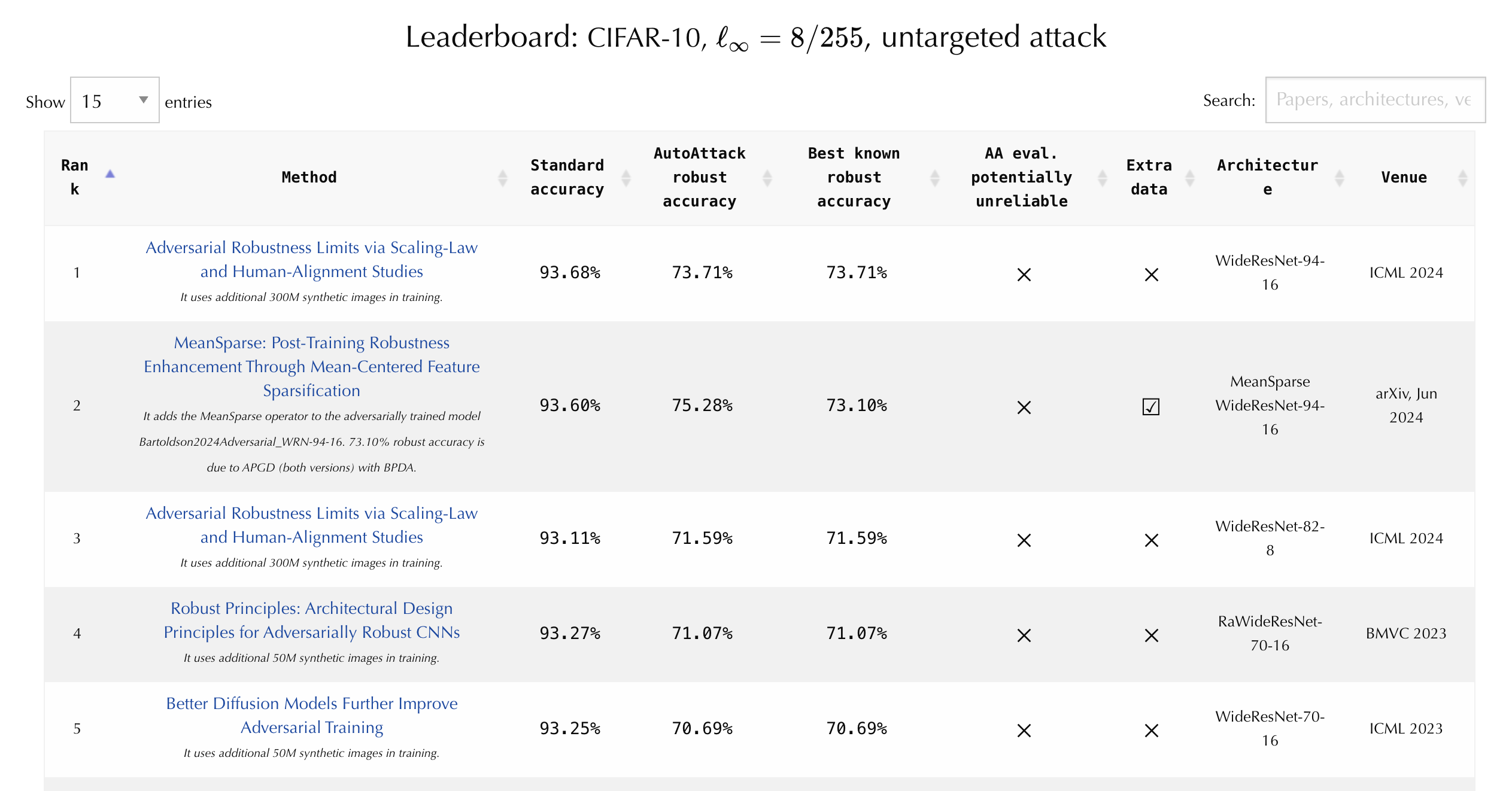
Today, the most robust image classifiers are trained with a more sophisticated version of one of the earliest defenses: adversarial training, or training the model to correctly classify perturbations which are continually generated by an adversary. A critical ingredient is that the perturbations must be freshly computed in each training iteration, since a specific perturbation is easy to defend against. The key differences now are that advances in generative modeling have enabled scaling up the training dataset from CIFAR-10’s original 50K training images to millions of synthetic images, and hardware advances have enabled training much bigger models for much longer. This is the approach taken by the team who trained the model that currently sits at the top of the RobustBench leaderboard (Bartoldson et al., 2024).
The same authors conducted a scaling study which trained many models across varying levels of compute and data quality to fit scaling curves and predict what further investments in compute would yield. Eyeballing their curves, a roughly GPT-4 sized training run would achieve roughly 85% robust accuracy, in the vicinity of where the same authors also estimated human robustness with a human study.1 This would cost about $10M at current H100 prices, which is at least ten million times more expensive than training a model to 85% clean accuracy. So, it is likely well within our physical capabilities today to train an image classification model that is roughly as robust against adversarial examples as humans, though there hasn’t been anyone willing to fund such an effort.
Back in the realm of LLMs, even a ten-fold increase in the cost of training is daunting. Complicating matters further, the expensive but feasible research results achieved on image classification assume perfect knowledge of test-time attacks, while attackers in the real world offer no such affordances. There are still regular discoveries of novel attacks, as well as attack techniques used by human experts which are difficult to proceduralize with code or LLMs. Such attacks are difficult or impossible to train against directly.
Much of agent security work today focuses on securing input and output channels — for instance by isolating untrusted data, detecting misbehavior with classifiers, or minimizing the means through which malicious instructions can be carried out— accepting the vulnerability of models as a given. The security of software systems that undergird AI agents can be more straightforward to reason about and improve upon, and will benefit significantly from further advances in AI coding capabilities. But for now, there are no easy answers for securing agents that consume any channels of untrusted information.
-
The authors estimate human performance at around 90%, though this is a generous upper bound on human performance since the study subjects were shown images optimized against neural networks, and not images optimized against them. ↩